Why You Should Not Use RabbitMQ for Real-Time Messaging
RabbitMQ is used to decouple systems
RabbitMQ is designed as a messaging system to decouple systems. The sooner you realize this, the sooner you can learn to use RabbitMQ optimally. I am not saying that you cannot use RabbitMQ outside of its main design, but you are left with dealing with some difficult side effects. Like a man on a boat paddling upstream, it can be possible, but requires a lot of work.
Let’s take a look at why RabbitMQ is designed for decoupling systems. RabbitMQ is centered around message queues and itself is a message broker whose primary job is to manage multiple message queues. The way RabbitMQ allows for decoupling is by not requiring the publisher and consumer of messages to be active simultaneously. In contrast to a client/server architecture where, in order for a transaction to be performed, both the client and server must communicate simultaneously. With RabbitMQ, the publisher can deliver messages to a message queue without knowledge of the consumer being present. The consumer can later come online and consume those messages without the publisher being present. This workflow is known as “store and forward”. RabbitMQ is very good at storing your messages and forwarding those messages to interested consumers.
Some developers might feel that there is a need for application level acknowledgment of messages because they don’t trust middleware systems to reliably deliver those messages. This misplaced trust leads them to create tightly coupled systems where both ends of the message communication must always be present. There are some cases where application level acknowledgment is necessary, but those cases are largely exaggerated due to misplaced trust and fear of middleware systems. The sooner that you understand how to use RabbitMQ for reliable communication and gain trust through practice, the sooner you can reap the benefits that RabbitMQ offers.
I used RabbitMQ in many production systems for both batch and real-time communication. When used for real-time communication, RabbitMQ yields some unwanted consequences that you will regret. Below I share my experiences on when NOT to use RabbitMQ.
Do not use RabbitMQ for real-time chat applications
Real-time chat applications is a category of applications that prefers instant delivery of messages rather than reliability. RabbitMQ is designed for reliability first, but not for real-time message communication. You can certainly use RabbitMQ for real-time communication as I have in the past, but when the system misbehaves, you are in for some surprises.
Surprise #1: Flooding RabbitMQ with presence or heartbeat messages.
One of the main features of a real-time chat application is the roster of users or bots that are currently online. The roster is equivalent to the buddy list in your favorite chat application that shows who is currently online, away, offline, etc. This is one of the key information that differentiates a real-time chat application from other messaging applications. How would you implement this type of real-time presences detection in RabbitMQ since RabbitMQ does not provide a facility for your application to get notified when a client comes online and goes offline? The way I have done it in the past was to send presence messages which are broadcast to all interested parties. This presence message acts as a heartbeat to inform all other clients that I am still alive. This heartbeat is published periodically from each client and when received by other clients, it will be interpreted as recording that source client is still alive and online. How often you send the heartbeat will significantly impact the number of heartbeat messages compared to real-time chat messages within the RabbitMQ message broker. The number of heartbeat messages grows exponentially with the number of clients that are connected since each one has to broadcast the messages to almost everyone else. This growth will flood the RabbitMQ with heartbeat messages instead of real chat messages.
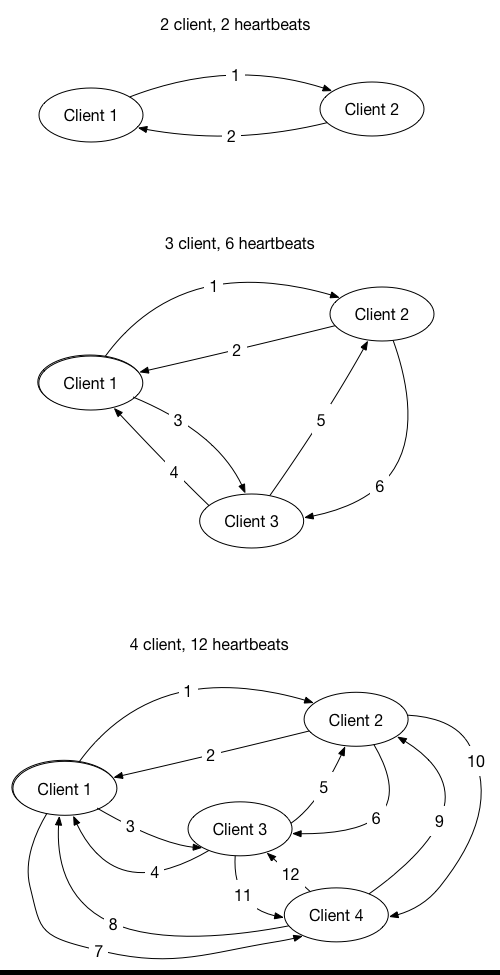
A solution to this problem is to create a central process that manages the online/offline status of each client. Now each client will only need to send the heartbeat to this central process. When the central process detects a client comes online or goes offline, only then this central process will broadcast the offline/online/away status to interested consumers. There remains a problem when a client constantly misses a heartbeat due to slow or unreliable networks.
A better solution for detecting an online/offline presence of client connections is not to use RabbitMQ but to use a connection-oriented server that can detect when a connection is severed. TCP socket connections are the most efficient way in connecting the client and server. WebSockets can also be used as it is built on top of TCP sockets. XMPP Servers are very good at doing this.
Be careful with implementing real-time chat applications that need to maintain a roster or buddy list of online/offline/away statuses. Using RabbitMQ will limit your scalability because RabbitMQ does not have a native way of detecting user presence status and requires you to use heartbeats to replicate this feature. Publishing too many heartbeats can flood your messaging systems and leave less room for user generated messages to be delivered in real time.
Surprise #2: Large volumes of messages will delay your heartbeat messages.
One of the main reason why you want to use RabbitMQ is the fact that it can reliably deliver messages. What this also means is that every message must be processed sequentially by a consumer. Imagine what would happen when we send a heartbeat message that is queued behind hundreds of other messages. When a consumer received this heartbeat messages, it might be too late. The main purpose of heartbeats is to serve as periodic messages to indicate that the heartbeat publisher is still alive. When the receiver of the heartbeat does not consume the heartbeat within the timeout interval, the receiver needs to mark this publisher as offline. This heartbeat becomes a time sensitive message. RabbitMQ is very good at making sure the message gets delivered to the consumer but does not guarantee when the messages will be delivered.
You can make this situation better if you create multiple connections, one connection dedicated to sending heartbeats and the other connections dedicated to sending chat messages. Unfortunately, once the messages arrive at the RabbitMQ message broker, there is no way to control the order of the messages being delivered to the consumer. Three is still a possibility that the heartbeat messages get delayed. You can play around with message and queue time-to-live (TTL) settings, but that is just a hack around an inherent limitation with RabbitMQ. Recognizing this limitation will save you from regrets in the future.
Do not use RabbitMQ for real-time data streaming
When I first started using RabbitMQ, I was impressed with its reliability and scalability. I treated it as something magical that can serve all of my messaging needs. In the past, I worked on a project that needed to stream real-time data to our client application. With RabbitMQ, it was a simple setup. All I had to do was to make the client a consumer of a message queue and create a publisher on the server to constantly publish data to the message queue whenever some new data was available. Everything was fine at first, performing beautifully. As more and more users came online, we started to experience issues with the ways on how we used RabbitMQ for real-time messaging.
Issue #1: Slow network makes a slow consumer.
Everything tested fine in our production environment when we first deployed the application. However, once in awhile, we noticed that our message queues started to accumulate an increasing number of unacknowledged messages or even worst the number of ready messages was growing rapidly. The unacknowledged messages indicate that the consumer was not processing the messages fast enough such that there was a queued up of messages on the client application. RabbitMQ prefetches messages from the message queue in order to increase the overall performance since it can fetch messages in the background. The increasing ready count on the message queue indicates the consumer, our client application, was not consuming as fast as we were producing messages. If this situation persisted, the message queue size would have overwhelmed RabbitMQ since it constantly had to write to the secondary storage (I.e. Hard drive, SSD). The increasing I/O demands would have also impacted other RabbitMQ citizens since they shared the same resources.
Here is what we did to solve the slow consumer problem. First, we had to configure every message and the message queue with a short time-to-live (TTL) value. The TTL value controls how long a message will live before it expires and ultimately be removed from the message queue. Leveraging the TTL feature in RabbitMQ, we ultimately solved the slow consumer and unbounded queue growth issue but using the TTL feature introduced another issue.
Issue #2: Short TTL values can result in lost messages.
When we configured the TTL value to be too small, sometimes our client applications would miss the most up to date messages. In a real-time streaming application, one of the primary goals of your client application is to display the most up to date information. When there are many updates to the same data element, it is acceptable to throw away the stale updates and only display the latest updates. This is known as the conflation technique. Unfortunately for us, when we configured the TTL feature, we were doing the opposite. We were keeping the oldest updates and letting the most recent updates expire. Since the message queue is a first-in-first-out queue, the oldest updates will need to get consumed before the newest updates. Once the update message gets pushed onto the queue, it must be consumed. In the case of a slow consumer, that consumer might still be consuming an old update while the latest updates expire.
Overall, this experience taught us that we needed to establish a lower bound network speed limit and declare that we will not support any client that does not meet the required network bandwidth. Also, we had to tune our TTL value such that it is large enough not to cause the latest update messages to be lost. The TTL value also determines the maximum size of your queue. The larger the value the more messages in your message queue for slower consumers.
With the TTL feature enabled, we could no longer guarantee that our client application gets the latest update. Therefore, we implemented another feature to periodically republish a snapshot of the latest updates for each data element in hopes that the client application would eventually get the latest updates.
If I had to do it over again, I would elect to use a bi-directional connection, such as TCP sockets, in order to implement a sliding message window to guarantee the client gets the latest updates with the option of dropping outdated updates. If you would like me to write more about this, please write a comment below.
Rethink using RabbitMQ for time sensitive messages
Since RabbitMQ is good at sending and broadcasting messages, you might be tempted to use it for streaming real-time data. I would advise not to use RabbitMQ for that purpose due to the fact that it is not designed for real-time applications. Real-time data applications are based on time-sensitive updates and RabbitMQ does not guarantee this.I hope after reading this article, you have gained some insights into why you should not use RabbitMQ for real-time messaging.